如果想快速部署体验,可参考单文件部署方案
通义千问 Qwen-7B-Chat 只需一个 ”exe“ 文件本地部署方案 (支持 openai api 及 Chatbox使用,CPU/GPU 兼容,Mac/Windows/Linux 兼容)
通义千问-7B(Qwen-7b)是什么
通义千问(Qwen-7B)是阿里云最新发布的一系列超大规模语言模型,这个牛气十足的大模型令人惊叹。基于Transformer架构,Qwen-7B系列汇聚了70亿参数。废话不多说,让我们一起来看看Qwen-7B的强大之处吧!
安装虚拟环境
1
2
3
4
# 安装虚拟环境
conda create -n qwen-7b python=3.10 -y
# 激活虚拟环境
conda activate qwen-7b
安装 pytorch
参考 https://pytorch.org/get-started/locally/ 我本地安装的 cuda 是 11.8 版本,所以安装代码如下,如果是用 cpu 跑的话,则省略本步骤,下面的代码会自动下载 cpu 版本的 pytorch
1
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
拉取代码并安装依赖
1
2
3
4
5
6
7
8
# 拉取代码
git clone https://github.com/QwenLM/Qwen-7B.git
# 进入代码目录
cd Qwen-7B
# 安装依赖
pip install -r requirements.txt
# 安装 web_demo 依赖
pip install -r requirements_web_demo.txt
启动 web_demo 快速体验(自动下载模型)
1
2
3
4
5
# 通过参数 --server-port 指定端口号,默认为 8000
# 通过参数 --server-name 指定服务地址,默认为 127.0.0.1
# 如果是用 cpu 跑的话,可以加上参数 --cpu-only
# 如果想生成一个用于公网访问的 url,可以加上参数 --share
python web_demo.py --server-port 8087 --server-name "0.0.0.0"
web demo 界面 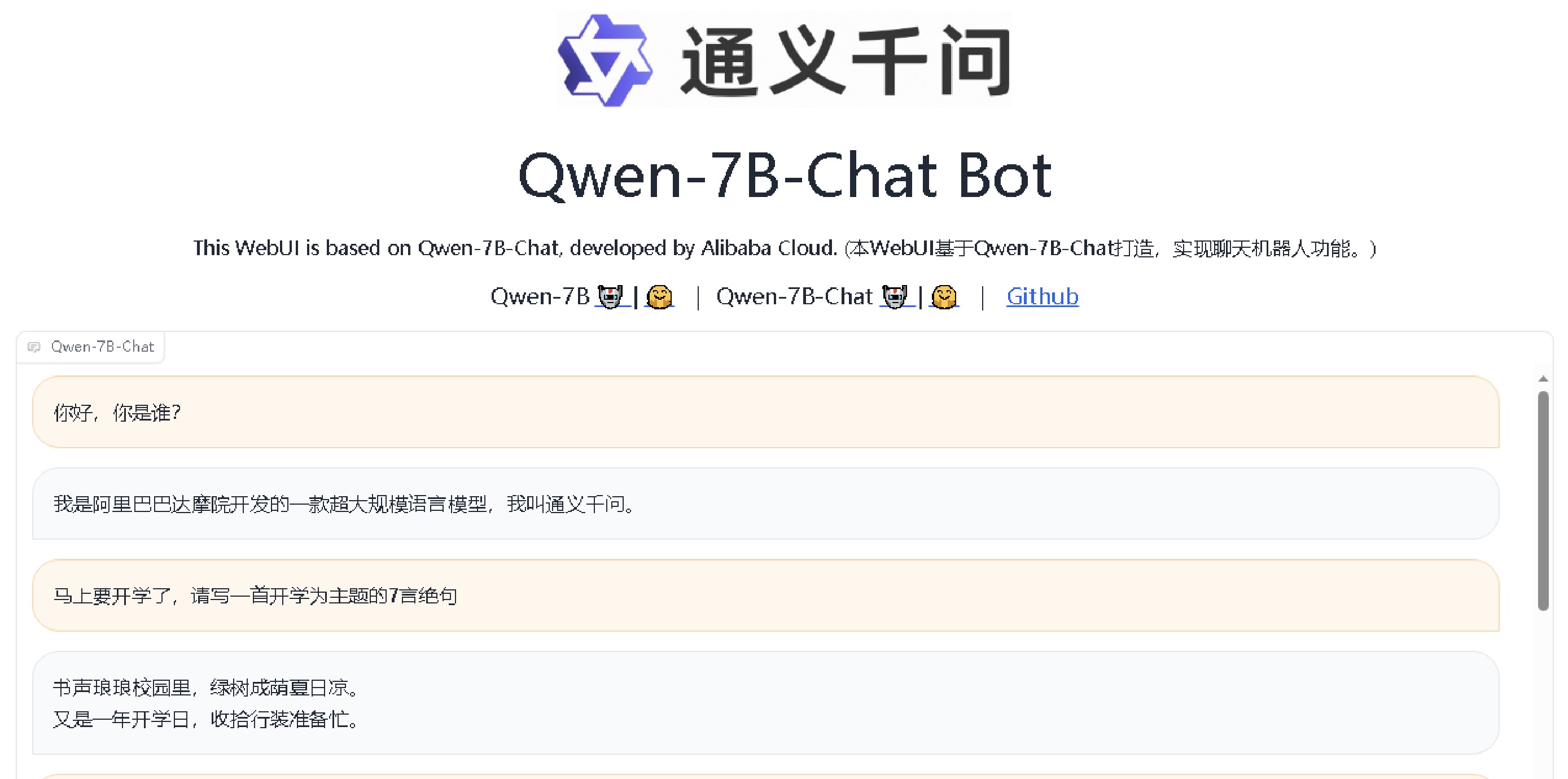
启动类 openai api 形式的接口
有个必要的依赖库需要先安装 pip install sse_starlette ,然后就可以启动了
1
2
3
4
# 通过参数 --server-port 指定端口号,默认为 8000
# 通过参数 --server-name 指定服务地址,默认为 127.0.0.1
# 如果是用 cpu 跑的话,可以加上参数 --cpu-only
python openai_api.py --server-port 8086 --server-name "0.0.0.0"
服务启动正常之后,就可以使用 openai 的客户端使用了,比如 chatbox、opencat 等等,亲测可用。 设置 api 的时候选择 openapi api 接口,api-key 为空即可。 下面为 chatbox 设置方法: 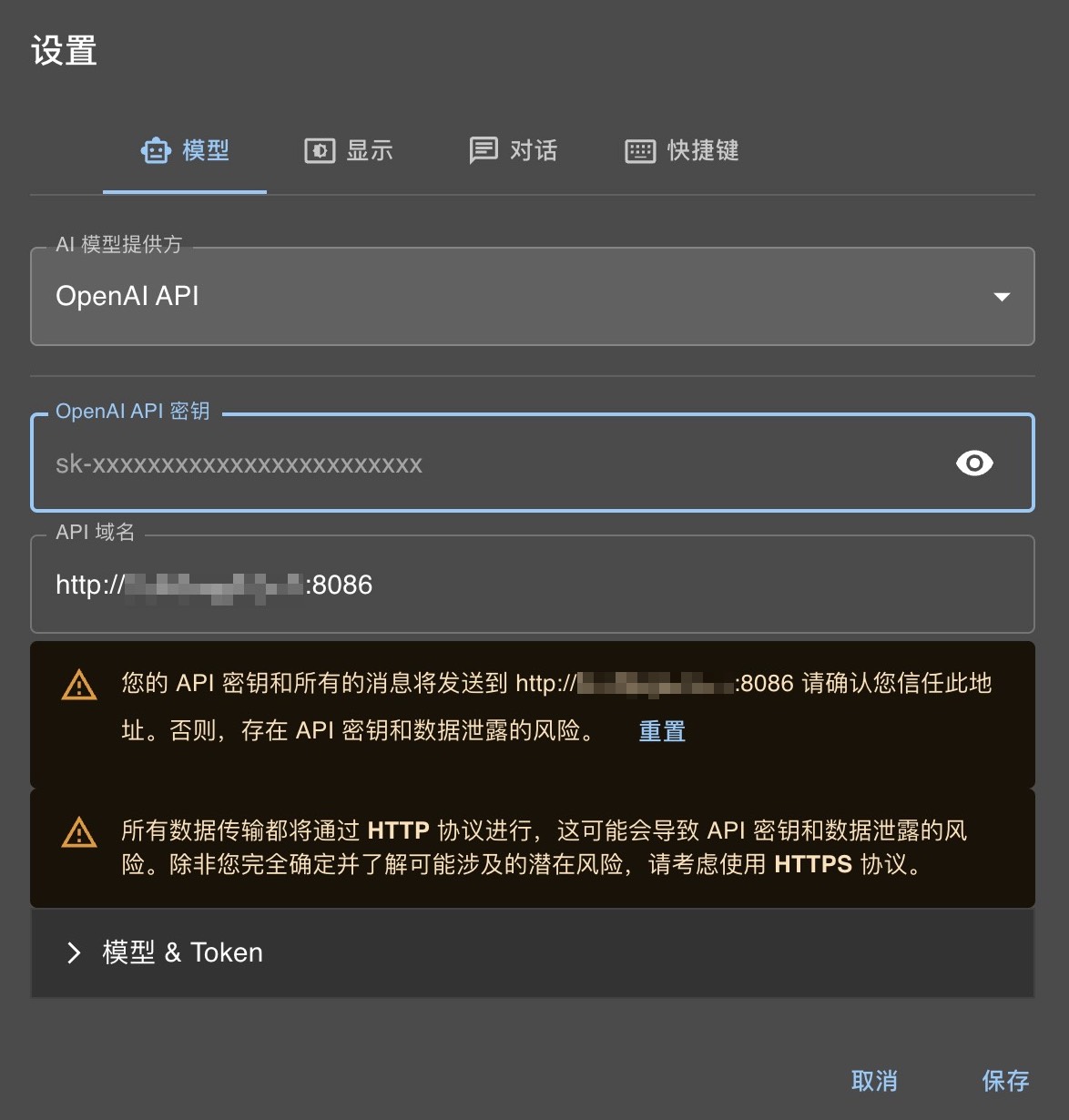 下面为 chatbox 对话效果
下面为 chatbox 对话效果 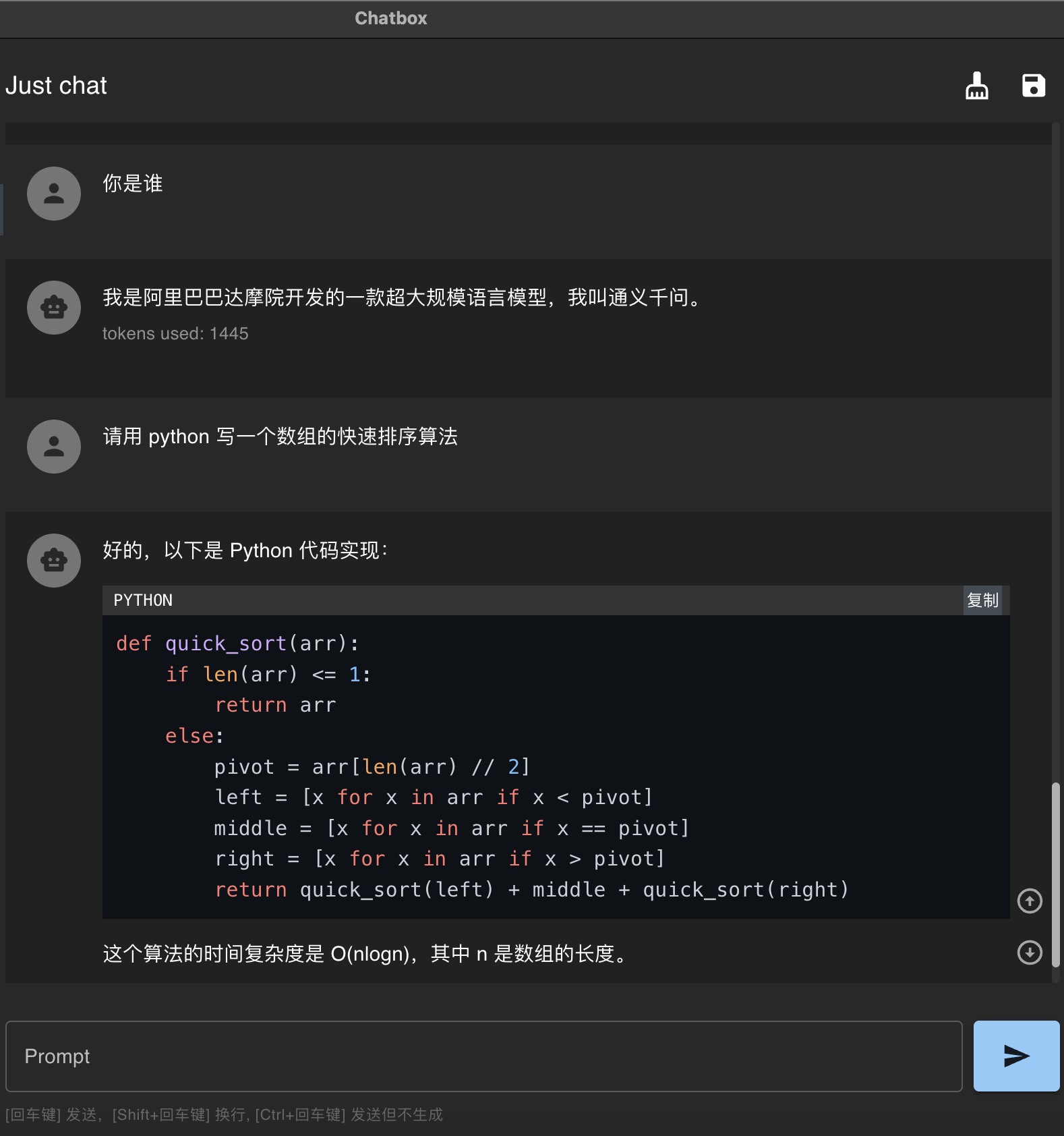
优化速度和显存占用
如果你的显卡支持fp16或bf16精度,官方推荐安装flash-attention来提高你的运行效率以及降低显存占用。(flash-attention只是可选项,不安装也可正常运行) 安装方法如下:
1
2
3
4
5
6
7
8
9
10
# 安装依赖
pip install ninja triton
# 从源码编译安装
git clone -b v1.0.8 https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
# 也可以直接从这里找到对应版本的whl文件进行安装
# https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.1
# 下方安装可选,安装可能比较缓慢。
# pip install csrc/layer_norm
# pip install csrc/rotary
模型量化部署/macOS 系统部署/cpu部署
官方刚上了个 qwen.cpp 项目,这是个类似 llama.cpp 的 qwen 版本,不过目前还在完善中,值得期待。
安装官方文档编译安装后,可以通过如下命令将模型量化为 int4 精度的模型,这样可以大幅度降低显存占用,加快推理速度。
1
python3 qwen_cpp/convert.py -i Qwen/Qwen-7B-Chat -t q4_0 -o qwen7b-q4_0-ggml.bin
其中 -t 参数支持如下量化精度:
- q4_0:4位有符号整数量化,使用16位浮点数缩放。
- q4_1:4位有符号整数量化,使用16位浮点数缩放和最小值。
- q5_0:5位有符号整数量化,使用16位浮点数缩放。
- q5_1:5位有符号整数量化,使用16位浮点数缩放和最小值。
- q8_0:8位有符号整数量化,使用16位浮点数缩放。
- f16:16位单精度浮点权重,不进行量化。
- f32:32位单精度浮点权重,不进行量化。
转换模型之后,可以通过如下命令使用 qwen.cpp 进行推理
1
./build/bin/main -m qwen7b-q4_0-ggml.bin --tiktoken Qwen-7B-Chat/qwen.tiktoken -p 你好
目前还没有提供类似 llama.cpp 的 server 服务模式,值得期待。
其他更大的模型
刚推出了个 140 亿参数的模型,以及 int4 量化版本 Qwen-14B-Chat Qwen-14B-Chat-Int4
推荐内容

