llamafile 是什么?
llamafile 是一种AI大模型部署(或者说运行)的方案, 与其他方案相比,llamafile的独特之处在于它可以将模型和运行环境打包成一个独立的可执行文件,从而简化了部署流程。用户只需下载并执行该文件,无需安装运行环境或依赖库,这大大提高了使用大型语言模型的便捷性。这种创新方案有助于降低使用门槛,使更多人能够轻松部署和使用大型语言模型。
llamafile 怎么用?
举个运行 Yi-6B-Chat 的例子
目前已发布了多个模型,可以在这里下:
为了更方便体验,本示例选了 Yi-6B-Chat.Q4_0.llamafile 这个模型, 只有 3.45GB, CPU 运行也只需要 4G 内存即可。模型地址:Yi-6B-Chat.Q4_0.llamafile
1、第一步,下载模型 Yi-6B-Chat.Q4_0.llamafile
2、第二步,运行
- linux 或 mac 要先添加执行权限
1 2 3 4 5 6
# 添加权限 chmod +x ./Yi-6B-Chat.Q4_0.llamafile # 运行模型 ./Yi-6B-Chat.Q4_0.llamafile # mac 可能会有安全提示,需要在 设置->安全与隐私 主动允许运行
- Windows先改文件名,添加
.exe后缀1 2 3 4
# 修改文件名,添加 .exe 后缀 Yi-6B-Chat.Q4_0.llamafile.exe # 运行模型 .\Yi-6B-Chat.Q4_0.llamafile.exe
3、第三步,用浏览器打开 http://127.0.0.1:8080/ 即可对话
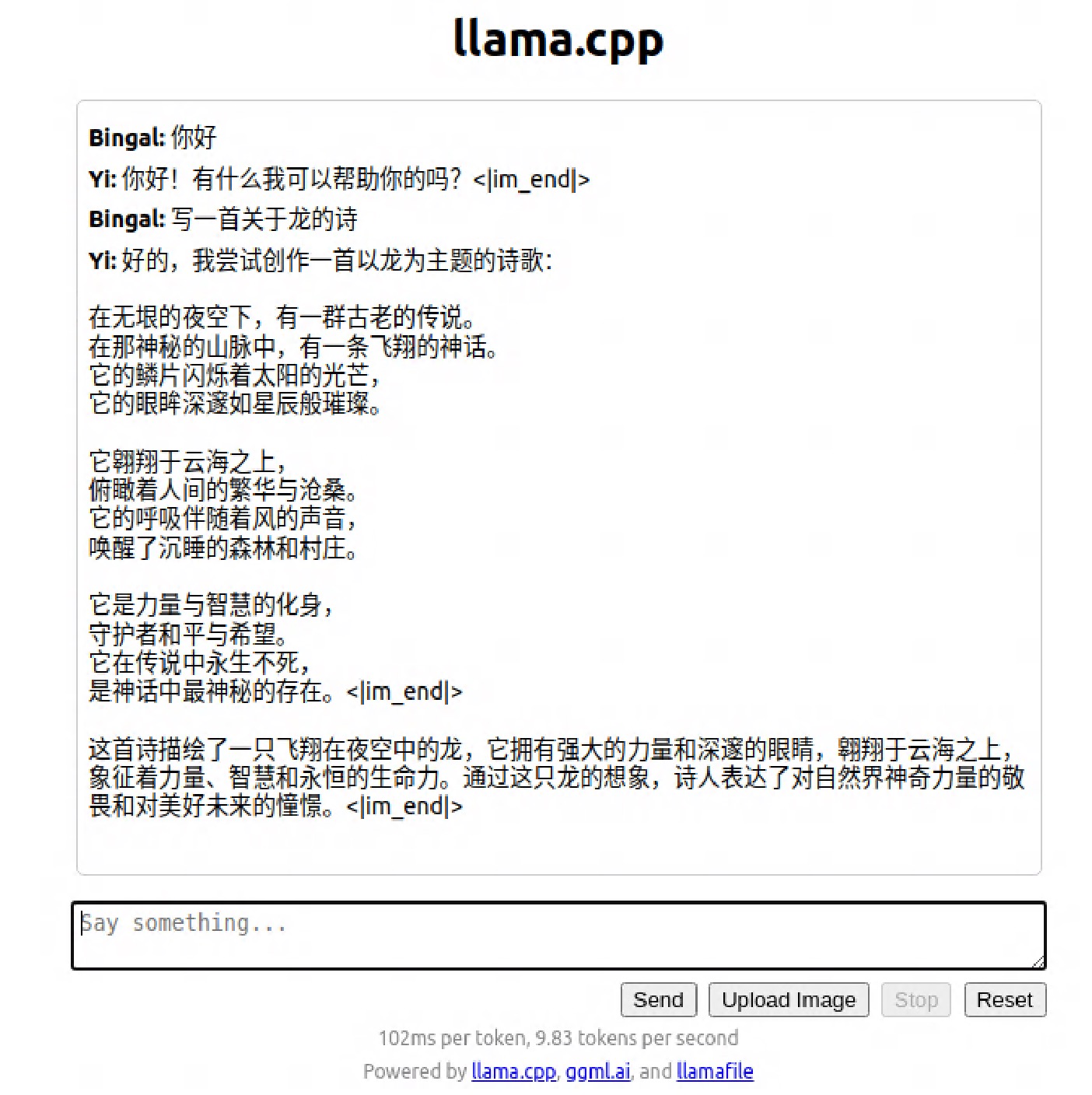
感觉是不是超级简单?超级丝滑?当然这只是最简单最基本的用法。该模型默认以server 方式运行,也提供了类 openai api 的接口。
Windows 系统不支持单个 exe 文件超过 4GB 的限制,所以需要分别下载 llamafile 和 gguf 模型运行;此外,也可以通过 Windows 的 WSL 子系统(Linux)运行,同样可以绕过 4GB 的限制
大于 4GB 模型,Windows 系统运行方式(以 Qwen1.5-7B-Chat 模型为例)
下载
llamafile-0.6.2.exe
下载地址:
https://www.modelscope.cn/api/v1/models/bingal/llamafile-models/repo?Revision=master&FilePath=llamafile-0.6.2.win.zip
下载后解压得到llamafile-0.6.2.exe文件。下载 Qwen1.5-7B-Chat-GGUF 模型
下载地址:
Qwen1.5-7B-Chat-GGUF: 70 亿参数的 q5_k_m 量化版本,5.15GB。打开
cmd或者terminal命令行窗口,进入模型所在目录1
.\llamafile-0.6.2.exe -m .\qwen1.5-7b-chat-q5_k_m.gguf -ngl 9999 --port 8080 --host 0.0.0.0
浏览器打开
http://127.0.0.1:8080即可开始聊天
chatbox 等 gpt 客户端使用设置
选择 openai api,设置 url 为对应的 ip 和端口即可,如下图所示: 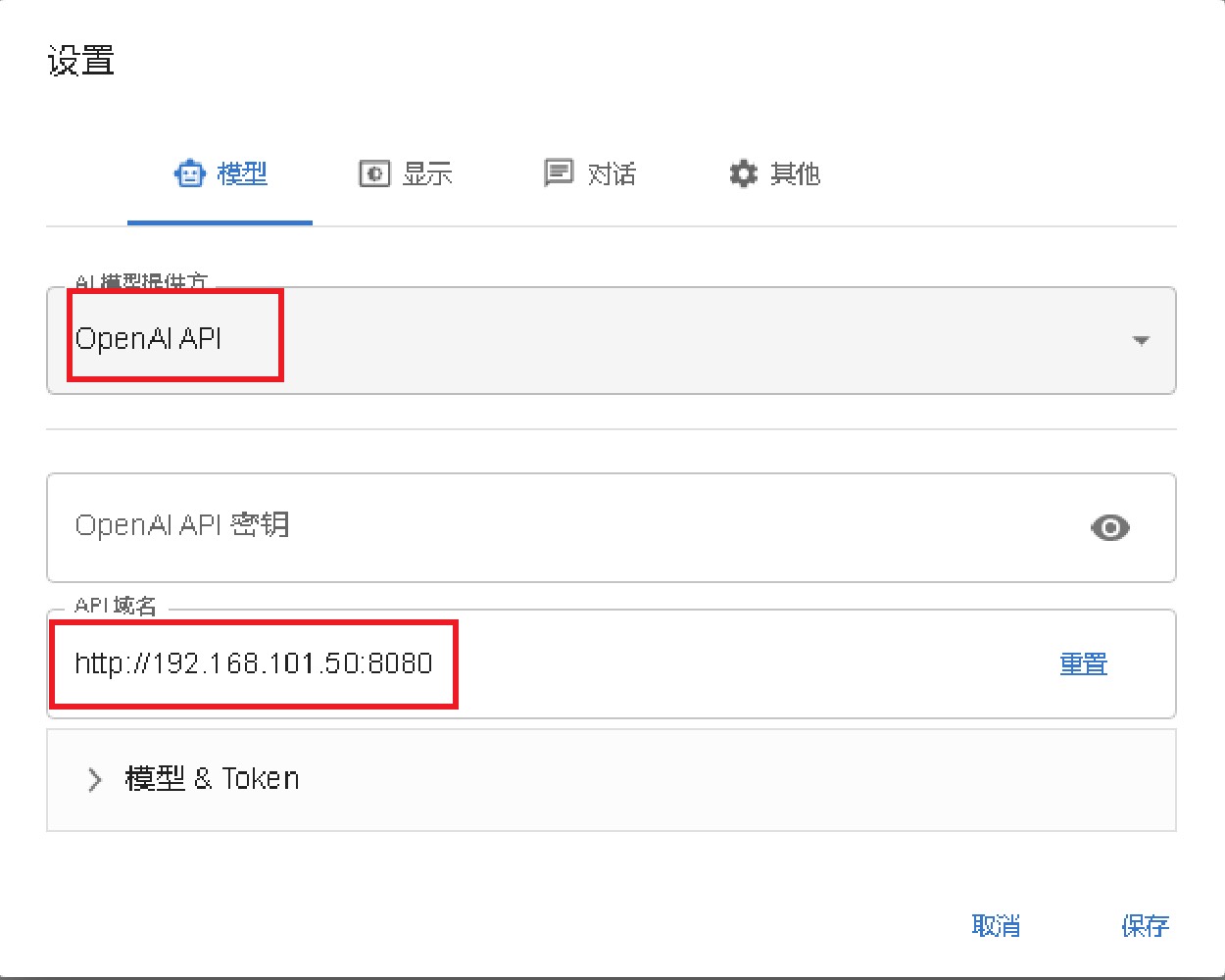
curl 请求
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# curl 使用
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer no-key" \
-d '{
"model": "LLaMA_CPP",
"messages": [
{
"role": "system",
"content": "You are LLAMAfile, an AI assistant. Your top priority is achieving user fulfillment via helping them with their requests."
},
{
"role": "user",
"content": "Write a limerick about python exceptions"
}
]
}' | python3 -c '
import json
import sys
json.dump(json.load(sys.stdin), sys.stdout, indent=2)
print()
'
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// 返回结果
{
"choices" : [
{
"finish_reason" : "stop",
"index" : 0,
"message" : {
"content" : "There once was a programmer named Mike\nWho wrote code that would often choke\nHe used try and except\nTo handle each step\nAnd his program ran without any hike.",
"role" : "assistant"
}
}
],
"created" : 1704199256,
"id" : "chatcmpl-Dt16ugf3vF8btUZj9psG7To5tc4murBU",
"model" : "LLaMA_CPP",
"object" : "chat.completion",
"usage" : {
"completion_tokens" : 38,
"prompt_tokens" : 78,
"total_tokens" : 116
}
}
python 接口调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#!/usr/bin/env python3
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8080/v1", # "http://<Your api-server IP>:port"
api_key = "sk-no-key-required"
)
completion = client.chat.completions.create(
model="LLaMA_CPP",
messages=[
{"role": "system", "content": "您是一个人工智能助手。您的首要任务是帮助用户实现他们的请求,以实现用户的满足感。"},
{"role": "user", "content": "写一首龙为主题的诗"}
]
)
print(completion.choices[0].message)
1
2
3
# 返回python对象
ChatCompletionMessage(content='There once was a programmer named Mike\nWho wrote code that would often strike\nAn error would occur\nAnd he\'d shout "Oh no!"\nBut Python\'s exceptions made it all right.', role='assistant', function_call=None, tool_calls=None)
命令行方式直接推理运行
1
./mistral-7b-instruct-v0.2.Q5_K_M.llamafile --temp 0.7 -p '[INST]Write a story about llamas[/INST]'
支持视觉的多模态小模型的例子
1
./llava-v1.5-7b-q4.llamafile --temp 0.2 --image lemurs.jpg -e -p '### User: What do you see?\n### Assistant:'
也可以直接运行 gguf 格式的模型
先下载编译好的二进制文件包
Release llamafile v0.6.2 · Mozilla-Ocho/llamafile (github.com)
当然,也可以从源码编译,下载完之后即可直接运行
- linux 或 mac
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# 假如下载的文件是 llamafile-0.6.1.zip # 先解压到 /youpath/llamafile-0.6.1 # 添加执行权限, /youpath/llamafile-0.6.1/bin 目录下的多个文件都添加执行权限 chmod +x /youpath/llamafile-0.6.1/bin/llamafile ... chmod +x /youpath/llamafile-0.6.1/bin/zipalign # 设置到环境变量 export PATH="/youpath/llamafile-0.6.1/bin:$PATH" # 假如模型所在路径是 /your-model-path/Qwen-7B-Chat.Q4_K_M.gguf llamafile \ -m /your-model-path/Qwen-7B-Chat.Q4_K_M.gguf \ --server \ --host 0.0.0.0 # 浏览器打开 http://you-ip:8080/ 即可对话 # 同样也支持命令行直接推理 # llamafile -h 可看详细参数说明
如何生成自己的 llamafile 可执行文件【此处用通义千问 Qwen-7b 举例】
- 下载最新的 llamafile,下载地址zip 包并解压:Release llamafile v0.6.2 · Mozilla-Ocho/llamafile (github.com)
- 下载模型Qwen-7B-Chat.Q4_K_M.gguf,下载地址:https://modelscope.cn/models/Xorbits/Qwen-7B-Chat-GGUF/files ,假如下载保存的路径是:
/data/Qwen-7b/Qwen-7B-Chat.Q4_K_M.gguf - 创建文件
/data/Qwen-7b/.args,内容如下:1 2 3 4 5 6 7
-m Qwen-7B-Chat.Q4_K_M.gguf --host 0.0.0.0 -ngl 9999 ...
- 拷贝 llamafile 压缩包 bin 目录下的 llamafile 文件并重命名
cp /data/llamafile-0.6.2/bin/llamafile /data/Qwen-7b/Qwen.llamafile - 拷贝 llamafile 压缩包 bin 目录下的 llamafile 文件并重命名
cp /data/llamafile-0.6.2/bin/zipalign /data/Qwen-7b/zipalign - 目录结构(总共 4 个文件)
1 2 3 4 5
# ls /data/Qwen-7b/ .args Qwen-7B-Chat.Q4_K_M.gguf Qwen.llamafile zipalign - 执行打包
1 2 3 4 5
cd /data/Qwen-7b/ zipalign -j0 \ Qwen.llamafile \ Qwen-7B-Chat.Q4_K_M.gguf \ .args
- 执行完成之后,就生成了文件
Qwen.llamafile - 运行模型
1 2
cd /data/Qwen-7b/ ./Qwen.llamafile
- 浏览器打开
http://127.0.0.1:8080/即可访问对话界面
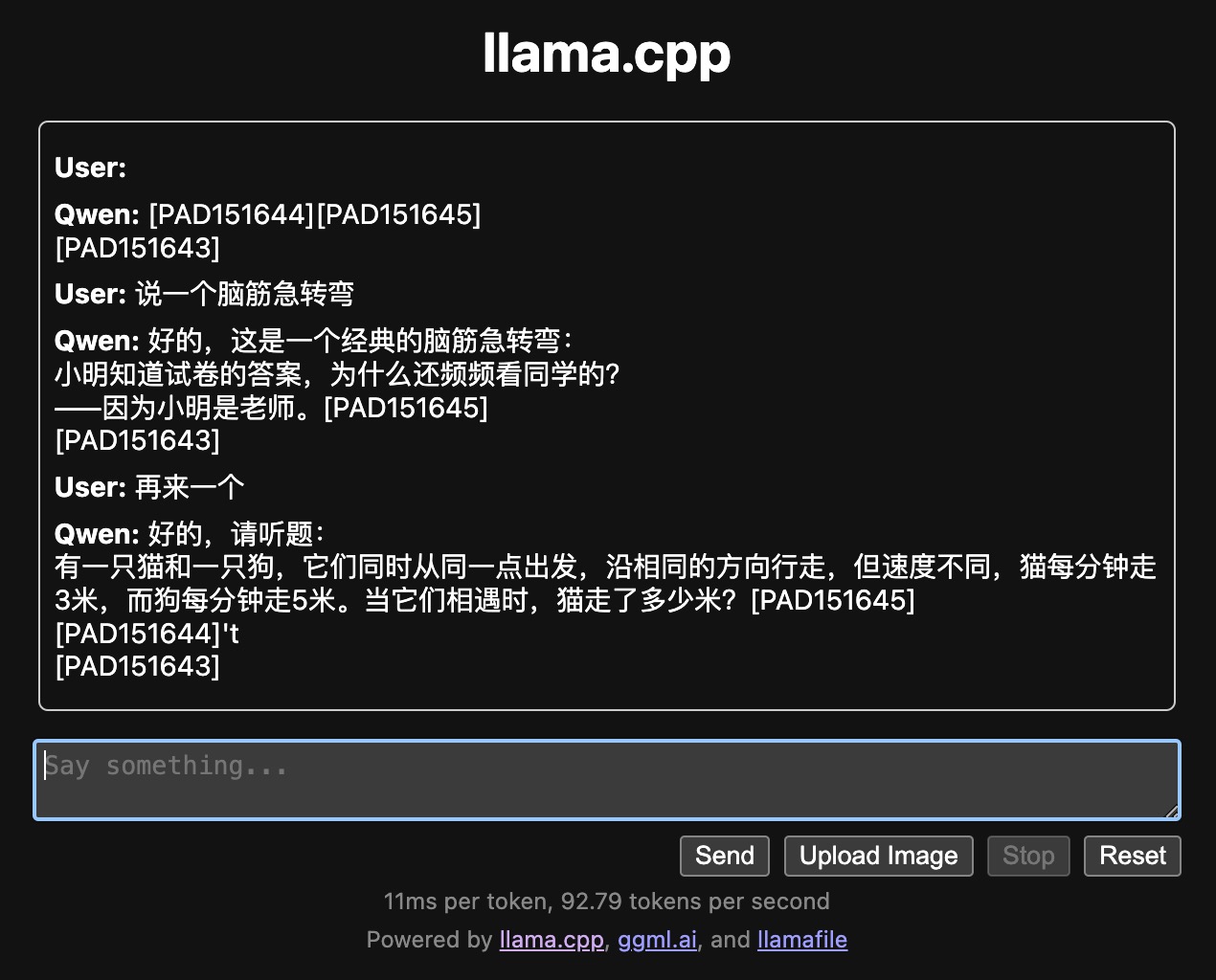
| *特别说明 :由于 llama.cpp对qwen tokenizer的支持有限,对话的时候,经常会有这样的内容结尾 [PAD151645][PAD151643], 两串内容分别对应< | im_end | >和< | endoftext | >, 如果是程序使用,可以考虑针对该内容进行一些删除等后置处理* |
modelscope.cn 的模型集合列表
| 模型 | 模型大小 | 下载地址 | 使用示例 | 说明 |
|---|---|---|---|---|
| Qwen-7B-Chat | 4.23GB | Qwen-7B-Chat-q4_0.llamafile | 示例 | 中英文对话 |
| Qwen-14B-Chat | 7.65GB 14.06GB | Qwen-14B-Chat-q4_0.llamafile Qwen-14B-Chat-q8_0.llamafile | - | 中英文对话 |
| Qwen1.5-7B-Chat | 5.18GB | qwen1_5-7b-chat-q5_k_m.llamafile | - | 中英文对话 |
| Qwen1.5-14B-Chat | 9.84GB | qwen1_5-14b-chat-q5_k_m.llamafile | - | 中英文对话 |
| Qwen1.5-0.5B-Chat | 420.57MB | qwen1_5-0_5b-chat-q4_k_m.llamafile | - | 中英文对话 |
| Qwen1.5-14B-Chat | 1.17GB | qwen1_5-1_8b-chat-q4_k_m.llamafile | - | 中英文对话 |
| Baichuan-13B-Chat | 7.06GB | Baichuan-13B-Chat-q4_0.llamafile | - | 中英文对话 |
| OrionStar-Yi-34B-Chat | 19.27GB | OrionStar-Yi-34B-Chat-q4_0.llamafile | - | 中英文对话 |
| CodeLlama-7b-Instruct | 3.59GB | CodeLlama-7b-Instruct-q4_0.llamafile | 示例 | 中英文对话、擅长写代码 |
| CodeFuse-QWen-14B | 7.65GB | CodeFuse-QWen-14B-q4_0.llamafile | - | 中英文对话、擅长写代码 |
| Yi-6B-Chat | 3.45GB | Yi-6B-Chat-q4.llamafile | 示例 | 中英文对话 |
| LLaVA-1.5-7B | 3.99GB | llava-v1.5-7b-q4.llamafile | 示例 | 英文视觉多模态 |
| Yi-VL-6B | 3.61GB | Yi-VL-6B-q4_0.llamafile | - | 中英文视觉多模态 |
| Ph-2 | 2.78GB | phi-2.Q8_0.llamafile.llamafile | - | 英文对话、微软出品 |
| TinyLlama-1.1B-Chat-v1.0 | 1.12GB | TinyLlama-1.1B-Chat-v1.0.Q8_0.llamafile | - | 英文对话 |
llamafile 是如何工作的
llamafile 是一个可执行的 LLM(大型语言模型),您可以在自己的计算机上运行它。它包含给定开源 LLM 的权重以及在实际运行该模型时所需的一切。这一切都是通过将 llama.cpp 与 Cosmopolitan Libc 结合实现的。其中 llama.cpp 提供了模型的运行环境,Cosmopolitan Libc 是个跨平台的 C 标准库(支持Linux + Mac + Windows + FreeBSD + OpenBSD + NetBSD + BIOS,7大平台),提供了跨平台的支持以及其他有用的功能。
- llamafile 可以在多种 CPU 微架构上运行。我们在 llama.cpp 中添加了运行时调度,使得新的 Intel 系统可以使用现代 CPU 功能,而不会牺牲对旧计算机的支持。
- llamafile 可以在多种 CPU 架构上运行。我们通过将 AMD64 和 ARM64 构建与一个 shell 脚本拼接在一起来实现这一点,该脚本启动合适的版本。我们的文件格式与 WIN32 和大多数 UNIX shell 兼容。它还可以轻松地(由您或您的用户)转换为平台本地格式,在需要时。
- llamafile 可以在六种操作系统上运行(macOS、Windows、Linux、FreeBSD、OpenBSD 和 NetBSD)。如果您制作自己的 llama 文件,您只需使用 Linux 风格的工具链构建一次代码即可。我们提供的基于 GCC 的编译器本身就是一个真正可移植的可执行文件,因此您可以从您最喜欢的开发操作系统上为这六个操作系统构建软件。
- LLM 的权重可以嵌入到 llamafile 中。我们将 PKZIP 支持添加到了 GGML 库中。这允许未压缩的权重直接映射到内存中,类似于自解压归档。它使在线分发的量化权重能够与兼容版本的 llama.cpp 软件前缀相结合,从而确保其最初观察到的行为可以无限期地复现。
- 最后,使用llamafile项目中的工具,任何人都可以创建自己的 llamafile,使用您想要的任何兼容模型权重。然后,可以将这些 llamafile 分发给其他人,他们可以轻松地使用它们,无论他们使用的是什么类型的计算机。
llamafile支持以下操作系统(最低标准安装说明):
- Linux:内核版本2.6.18或更高版本(支持ARM64或AMD64架构),适用于任何如RHEL5或更新版本的分发版
- macOS:macOS 14 Sonoma(Darwin版本23.1.0)或更高版本(支持ARM64或AMD64架构,但仅ARM64架构支持GPU加速),Darwin内核版本15.6或更高版本理论上应该得到支持,但我们目前无法进行实际测试。
- Windows:windows 8或更高版本(仅支持AMD64架构)
- FreeBSD: FreeBSD 13或更高版本(支持AMD64或ARM64架构,理论上GPU应可工作)
- NetBSD:NetBSD 9.2或更高版本(仅支持AMD64架构,理论上GPU应可工作)
- OpenBSD:OpenBSD 7或更高版本(仅支持AMD64架构,不支持GPU加速)
llamafile支持以下CPU类型:
- AMD64架构的微处理器必须支持SSSE3指令集。如果不支持,llamafile将显示错误信息并无法运行。这意味着,如果您使用的是Intel CPU,至少需要是Intel Core或更新系列(约2006年以后);如果是AMD CPU,至少需要是Bulldozer或更新系列(约2011年以后)。如果您的CPU支持AVX或更高级的AVX2指令集,llamafile将利用这些特性以提升性能。目前AVX512及更高级指令集的运行时调度尚未得到支持。
- ARM64架构的微处理器必须支持ARMv8a+指令集。从Apple Silicon到64位Raspberry Pis的设备都应该兼容,只要您的权重数据能够适应内存容量。
llamafile 对 GPU 的支持说明
- 在搭载 MacOS 的 Apple Silicon 系统上,只要安装了 Xcode 命令行工具,Metal GPU 就应该能够正常工作。 在 Windows 系统上,只要满足以下两个条件,GPU 就应该能够正常工作:(1)使用我们的发行版二进制文件;(2)传递 -ngl 9999 标志。如果您只安装了显卡驱动程序,那么 llamafile 将使用 tinyBLAS 作为其数学内核库,这对于批处理任务(例如摘要生成)来说会慢一些。为了获得最佳性能,NVIDIA GPU 用户需要安装 CUDA SDK 和 MSVC;而 AMD GPU 用户则需要安装 ROCm SDK。如果 llamafile 检测到 SDK 的存在,那么它将为您系统编译一个原生模块,该模块将使用 cuBLAS 或 hipBLAS 库。您还可以通过启用 WSL 上的 Nvidia CUDA 并在 WSL 中运行 llamafiles 来使用 CUDA。使用 WSL 的额外好处是,它允许您在 Windows 上运行大于 4GB 的 llamafiles。
- 在 Linux 系统上,如果满足以下条件,Nvidia cuBLAS GPU 支持将在运行时编译:(1)安装了 cc 编译器;(2)传递 -ngl 9999 标志以启用 GPU;(3)在您的机器上安装了 CUDA 开发工具包,并且 nvcc 编译器在您的路径中。
- 如果您的机器中同时有 AMD GPU 和 NVIDIA GPU,那么您可能需要通过传递 –gpu amd 或 –gpu nvidia 来指定要使用的 GPU。
- 如果由于任何原因无法在运行时编译和动态链接 GPU 支持,llamafile 将回退到 CPU 推理。
问题
项目目前正处于积极的开发阶段,这意味着功能会不断迭代更新,用户体验也会持续优化。不过,由于技术发展的快速性,可能会出现一些兼容性问题。开发者正致力于解决这些问题,以确保未来的大模型使用更加便捷。
我遇到了 gcc 版本不一致的问题,以及虚拟机里运行提示 cpu 不支持 SSE3的问题
推荐阅读
本文只介绍了简单的使用,还有更多用法和功能以及注意事项,可以参考项目网址 https://github.com/Mozilla-Ocho/llamafile
国内下载大模型的极速通道:替代 Huggingface 的优选方案
AI服务推荐:那些免费好用的 ChatGPT 平替产品(效果超越 ChatGPT3.5)
