如果想快速部署体验,可参考单文件部署方案
CodeLlama 是什么
Code Llama 是 Meta 开源的基于 Llama 2 的用于辅助代码生成的大模型,其中包含基础模型 (Code Llama)、Python 专业化模型 (Code Llama - Python) 和指令跟随模型 (Code Llama - Instruct),每个模型都有 7B、13B 和 34B 参数的版本。
模型说明
Code Llama 基础模型
- 简介:这些模型构成了代码生成的基石。
- 模型参数规模:它们分为三个大小:7B、13B和34B参数。
- 训练特点:
- 7B和13B模型使用了”填充目标”(infilling objective)策略进行训练,使它们能够在集成开发环境(IDE)中自动完成文件中段落的代码。
- 34B模型并未使用此策略。
- 数据和初始化:所有模型均从Llama 2模型权重开始初始化,并在一个主要包含代码的数据集上使用500B tokens进行训练。此外,这些模型都已针对长上下文经过优化。
Code Llama - Python专用模型
- 简介:这些模型专为Python代码生成而设计。
- 模型参数规模:它们同样分为7B、13B和34B参数三个版本。
- 研究目的:这些模型的目标是探讨针对特定编程语言的模型与通用代码生成模型之间的性能差异。
- 数据和初始化:这些模型从Llama 2模型权重开始初始化,并在Code Llama数据集上使用500B tokens进行训练。随后,它们在一个以Python为主的数据集上针对100B tokens进行了进一步的训练。
- 特色:所有Code Llama - Python模型都在没有使用填充策略的情况下进行训练,并已优化以处理长上下文。
Code Llama - Instruct 模型
- 简介:这些模型在Code Llama的基础上微调,旨在更精确地遵循人类指示。
- 微调数据:这些模型接受了约5B tokens的额外微调。
下载模型
- 先在 Meta AI 网站填写个人信息并同意协议,提交之后会收到一封名为
Get started with Code Llama的邮件,里面有个https://download2.llamameta.net/*?Policy=...开头的链接。 - 克隆代码到本地
1 2 3 4 5 6
# 克隆代码 git clone https://github.com/facebookresearch/codellama.git # 进入代码目录 cd codellama # 执行下载命令 bash download.sh
按提示把邮件里的链接粘贴到终端,然后再按提示输入需要下载的模型,等待模型下载完成。
创建虚拟环境
1
2
3
4
5
6
7
8
9
10
# 创建虚拟环境,基于 python3.10 版
conda create -n codellama python==3.10 -y
# 激活虚拟环境
conda activate codellama
# 安装 pytorch 等必要的库
# 参考 https://pytorch.org/get-started/locally/
# 比如我的 cuda 版本是 11.8 安装方法如下
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# 安装 code llama 依赖
pip install -e .
测试 code llama 代码填充
具体可以查看 example_completion.py 代码,输入了两段代码片段,然后 code llama 会自动补全代码。
1
2
3
4
5
6
7
8
9
# 进入 codellama 目录
cd codellama
# 激活虚拟环境
conda activate codellama
# 假设下载的模型是 CodeLlama-7b
torchrun --nproc_per_node 1 example_completion.py \
--ckpt_dir CodeLlama-7b/ \
--tokenizer_path CodeLlama-7b/tokenizer.model \
--max_seq_len 128 --max_batch_size 4
输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
> initializing model parallel with size 1
> initializing ddp with size 1
> initializing pipeline with size 1
Loaded in 11.09 seconds
import socket
def ping_exponential_backoff(host: str):
>
"""
Ping a host with exponential backoff.
"""
# Set up a socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# Set up exponential backoff
backoff = 1
while True:
try:
# Try to connect
sock.connect((host, 80))
break
except ConnectionRefusedError:
# If connection
==================================
import argparse
def main(string: str):
print(string)
print(string[::-1])
if __name__ == "__main__":
>
parser = argparse.ArgumentParser(description="Reverse a string")
parser.add_argument("string", help="The string to reverse")
args = parser.parse_args()
main(args.string)
# python3 reverse_string.py --string "Hello World"
# Hello World
# dlroW olleH
# python3 reverse
==================================
出现这样的结果就说明 code llama 已经可以正常使用了。
在 VSCode 中使用 code llama
code llama 在 vscode 中使用,需要使用 vscode 的 continue 插件(官网),以及通过 这个项目 启动 api 服务。
安装 continue 插件
在 vscode 的插件搜索 continue(如下图),然后安装即可。

continue 配置 code llama
参考官方文档 continue 官方文档
修改配置文件 ~/.continue/config.py
方案 1
开启 api 服务,这里使用模型 CodeLlama-7b-Instruct
按照这里的说明 code-llama-for-vscode,下载 https://github.com/xNul/code-llama-for-vscode/blob/main/llamacpp_mock_api.py 到 codellama 目录下,然后执行下面命令即可启动 api 服务。如果要更改端口号,可以在 llamacpp_mock_api.py 文件中修改port: int = 8000,,默认是 8000 端口。
1
2
3
4
torchrun --nproc_per_node 1 llamacpp_mock_api.py \
--ckpt_dir CodeLlama-7b-Instruct/ \
--tokenizer_path CodeLlama-7b-Instruct/tokenizer.model \
--max_seq_len 512 --max_batch_size 4
修改配置文件
1
2
3
4
5
6
7
8
9
10
11
# 引入必要的库
from continuedev.src.continuedev.libs.llm.ggml import GGML
config = ContinueConfig(
# ... 修改对应的模型设置
models=Models(
default=GGML(
max_context_length=2048,
server_url="http://localhost:8000")
)
)
重启 vscode,点击左侧的 continue 插件图表,如下图  第一次运行需要等待比较长时间,插件会下载本地服务有关程序,以及 meilisearch (全文检索数据库)等文件。目前 continue 插件还是 beta 版,感觉还不是很稳定,很有可能会出现各种问题,目前只适合尝鲜,不适合正式使用。 等启动完成之后,就可以在插件窗口进行对话了,如下图:
第一次运行需要等待比较长时间,插件会下载本地服务有关程序,以及 meilisearch (全文检索数据库)等文件。目前 continue 插件还是 beta 版,感觉还不是很稳定,很有可能会出现各种问题,目前只适合尝鲜,不适合正式使用。 等启动完成之后,就可以在插件窗口进行对话了,如下图: 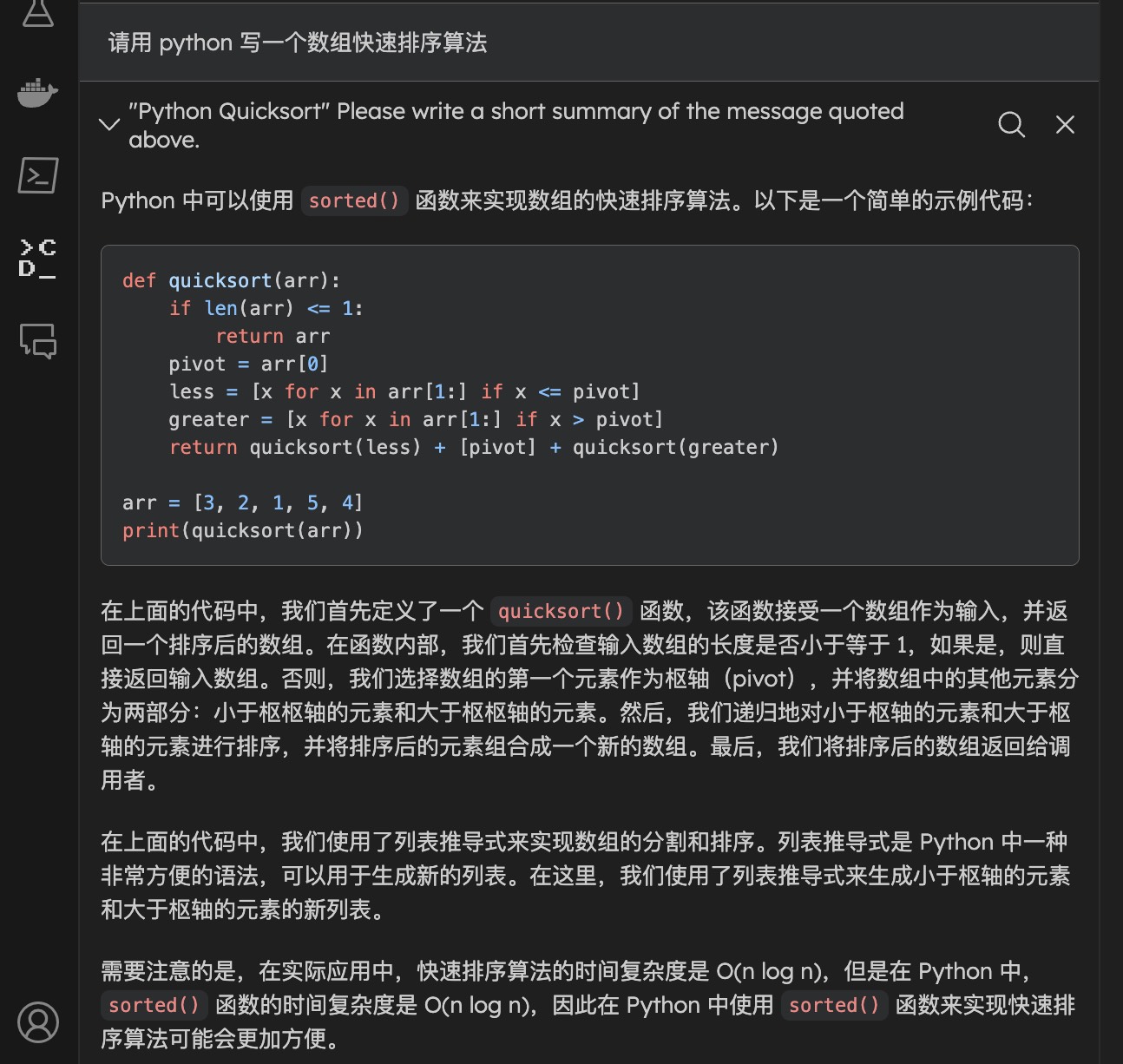
方案 2 (使用相对简单,直接从 huggingface 下载 CodeLlama-7b-Instruct-hf 模型)
本方案需要使用 FastChat项目
安装 FastChat
1
pip3 install "fschat[model_worker,webui]"
启动 FastChat OpenAI-Compatible RESTful APIs
1
2
3
4
5
6
# 启动控制器
python -m fastchat.serve.controller
# 启动模型worker
python -m fastchat.serve.model_worker --model-path codellama/CodeLlama-7b-Instruct-hf
# 启动 web服务
python -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 8000
修改 continue 插件的配置文件
1
2
3
4
5
6
7
8
9
10
11
12
from continuedev.src.continuedev.libs.llm.openai import OpenAI
config = ContinueConfig(
# ... 修改对应的模型设置
models=Models(
default=OpenAI(
api_key="EMPTY",
model="CodeLlama-7b-Instruct-hf",
api_base='http://localhost:8000/v1')
),
...
)
修改保存后,重启 vscode,使用方式和方案一一样。
通过 chatbox 使用 code llama
安装 FastChat
1
pip3 install "fschat[model_worker,webui]"
启动 FastChat OpenAI-Compatible RESTful APIs
1
2
3
4
5
6
# 启动控制器
python -m fastchat.serve.controller
# 启动模型worker
python -m fastchat.serve.model_worker --model-path codellama/CodeLlama-7b-Instruct-hf
# 启动 web服务
python -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 8000
启动 chatbox
注意要更新到最新版本的 chatbox,最新版本才支持自定义模型名称。 chatbox 设置 api 和模型,如下图  模型选择自定义模型,名称输入
模型选择自定义模型,名称输入 CodeLlama-7b-Instruct-hf 
设置完之后就可以进行对话了,如下图 
