如果想快速部署体验,可参考 llamafile 文件部署 CodeLlama-7b-Instruct
CodeFuse 是什么?
CodeFuse 是蚂蚁自研的代码生成专属大模型,根据开发者的输入提供智能建议和实时支持,帮助开发者自动生成代码、自动增加注释,自动生成测试用例,修复和优化代码等,以提升研发效率。目前已经发布了 CodeFuse-13B、CodeFuse-CodeLlama-34B、CodeFuse-StarCoder-15B 以及 int4 量化模型 CodeFuse-CodeLlama-34B-4bits。目前已在阿里巴巴达摩院的模搭平台 modelscope codefuse 和 huggingface codefuse 上线。值得一提的是,CodeFuse-CodeLlama-34B 基于 CodeLlama 作为基础模型,并利用 MFT 框架进行微调,在 HumanEval Python pass@1 评估中取得高达的74.4%(贪婪解码)的好成绩,甚至超过了 GPT-4(67%)的表现。对比数据如下:
| 模型 | HumanEval(pass@1) | 日期 |
|---|---|---|
| CodeFuse-CodeLlama-34B | 74.4% | 2023.9 |
| CodeFuse-CodeLlama-34B-4bits | 73.8% | 2023.9 |
| WizardCoder-Python-34B-V1.0 | 73.2% | 2023.8 |
| GPT-4(zero-shot) | 67.0% | 2023.3 |
| PanGu-Coder2 15B | 61.6% | 2023.8 |
| CodeLlama-34b-Python | 53.7% | 2023.8 |
| CodeLlama-34b | 48.8% | 2023.8 |
| GPT-3.5(zero-shot) | 48.1% | 2022.11 |
| OctoCoder | 46.2% | 2023.8 |
| StarCoder-15B | 33.6% | 2023.5 |
| LLaMA 2 70B(zero-shot) | 29.9% | 2023.7 |
数据来自官方发布,仅供参考,4bits 版本测试结果 73.8% 超过了 GPT-4 的 67.0%。
非常期待能够看到基于该模型的应用或插件的出现,以使我们的编程更加高效。不过,目前官方提供的推理方案是基于 AutoGPTQ,对于普通用户来说可能并不友好。因此,笔者花费了一番功夫进行研究,找到了一个基于 llama-cpp-python 且使用 CodeFuse-CodeLlama-34B-4bits 推理方案的方法。借助这种方案,可以轻松部署一个类似 openai-API 的接口服务,然后通过 Chatbox 等 GPT 客户端进行对话使用,非常方便。
显存占用情况
| 精度 | 模型空载 | 输入2048 tokens + 输出1024 tokens | 输入1024 tokens + 输出2048 tokens |
|---|---|---|---|
| bfloat16 | 64.89GB | 69.31GB | 66.41GB |
| int4 | 19.09GB | 22.19GB | 20.78GB |
数据来自官方发布,笔者实际使用情况基本一致。
总的来说,如果你的显卡有 24G 显存,就可以全部由显卡推理。经过实践,发现显卡推理速度很快,对话过程顺畅。然而,如果显存不足,可以考虑使用 llama.cpp(llama-cpp-python)进行推理,因为它可以同时利用 CPU 和 GPU,即使显存不足也可以使用部分 CPU 推理或者使用内存来补充,但这样会显著降低推理速度。此外,llama.cpp(llama-cpp-python)还支持在 Mac 上使用,尤其是 Apple Silicon 版的 Mac 电脑,可以利用其 GPU 进行推理。
先看对话效果

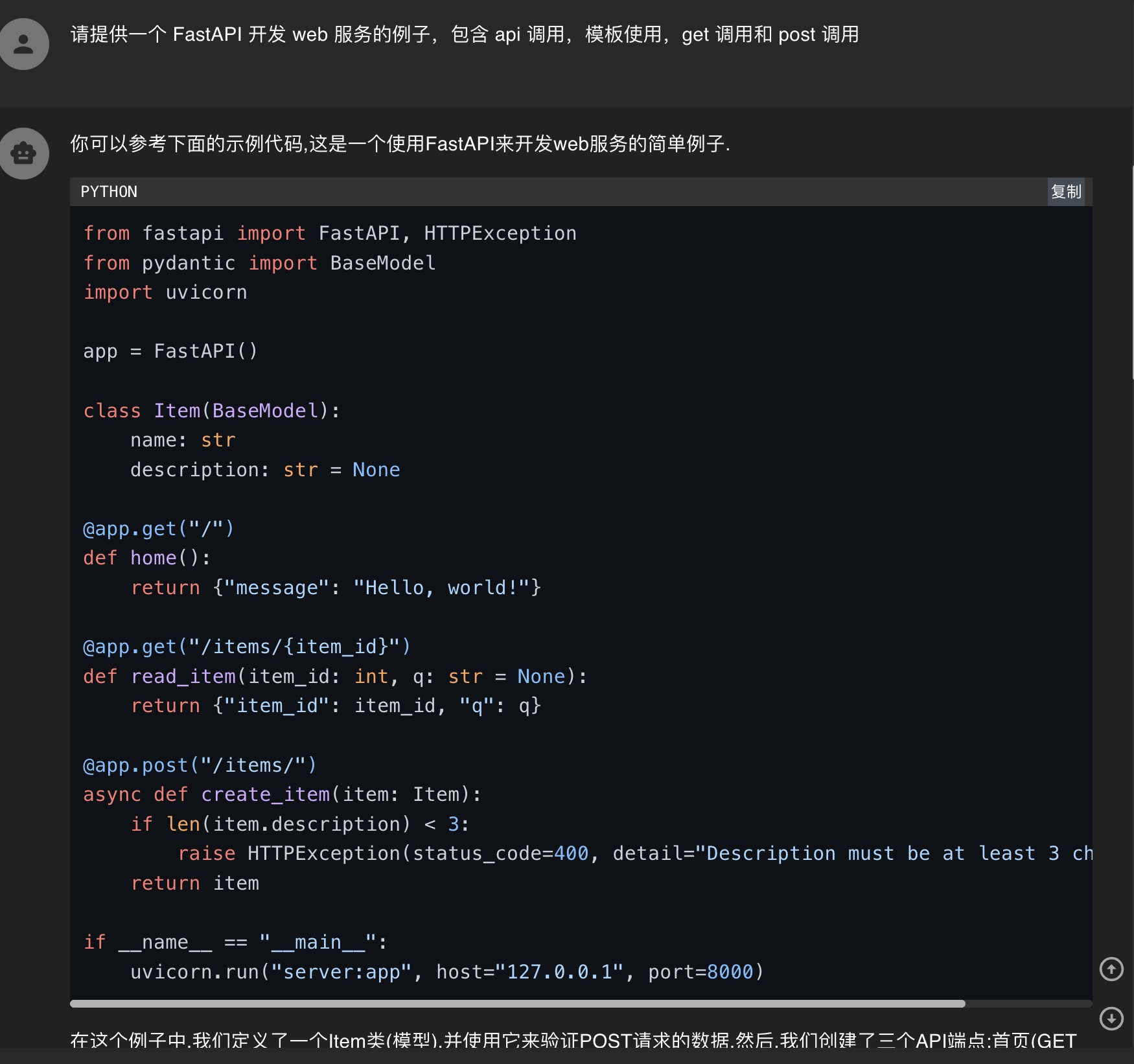
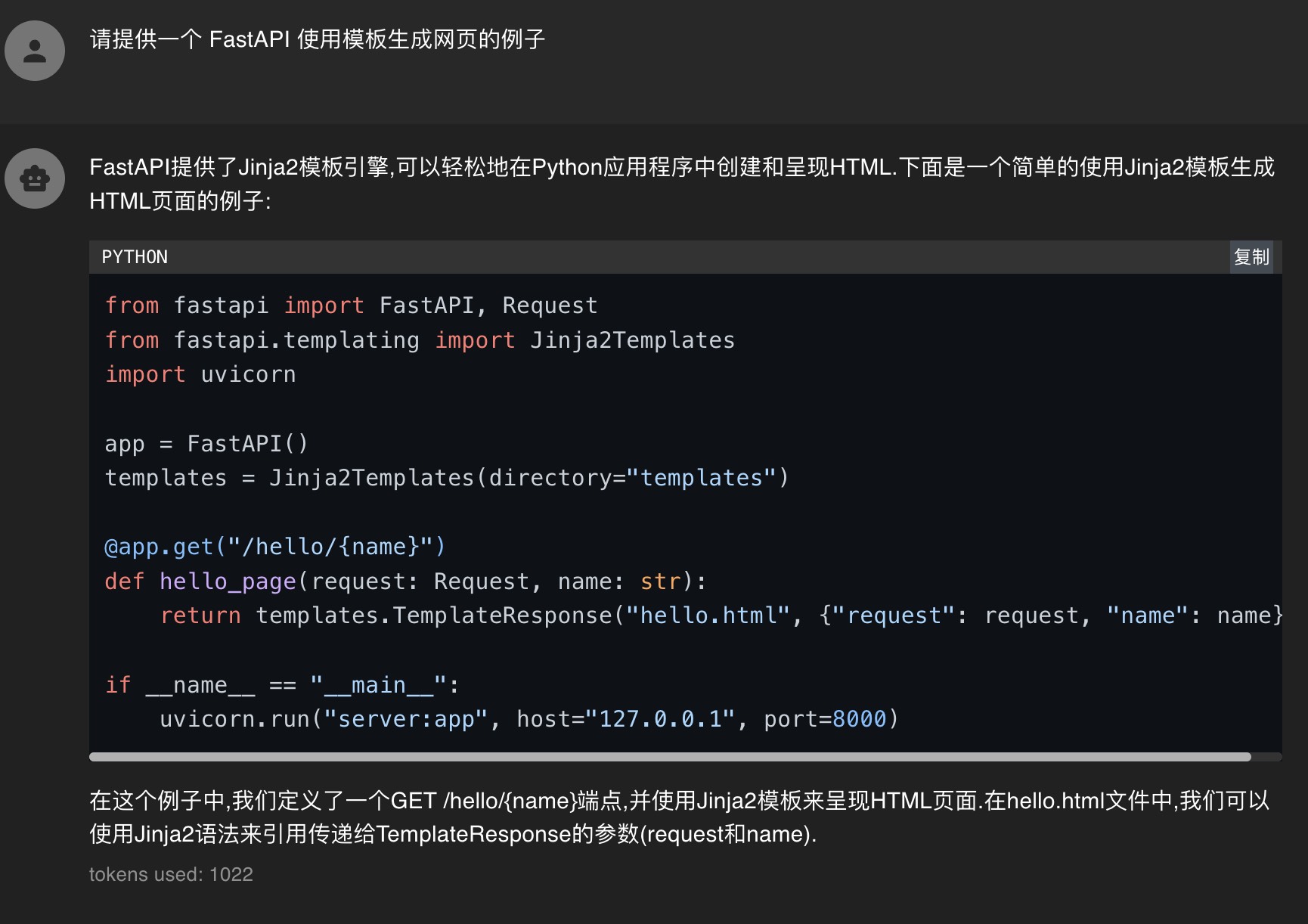
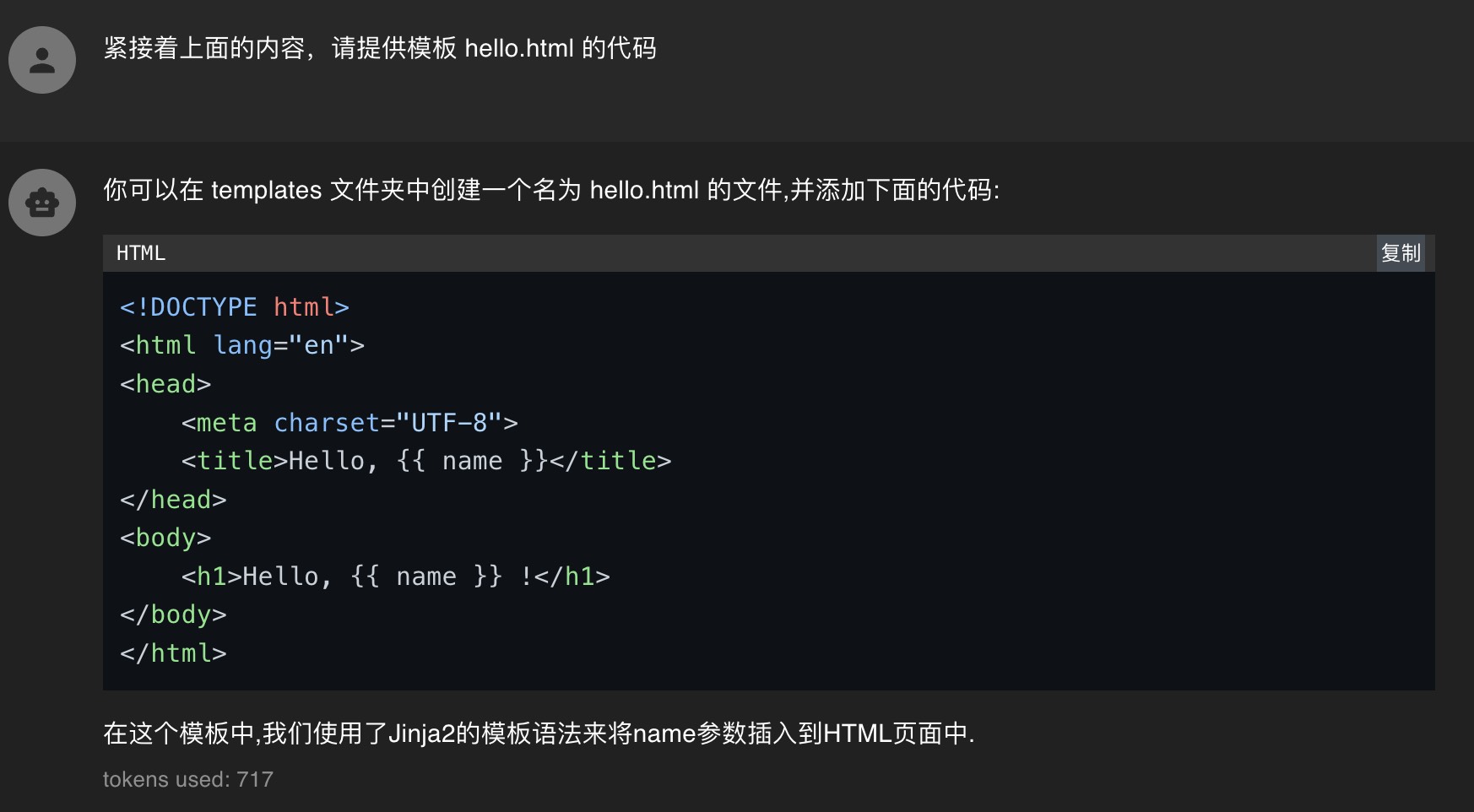
安装 llama-cpp-python
下面的安装环境是 Ubuntu 22.04 + Nvidia 显卡,其他系统环境,请参考官方文档 llama-cpp-python
前置条件
- 装好 Nvidia 显卡驱动和 cuda 库。
- 装好 c 编译环境,比如 gcc、g++、cmake 等等。
1 2
sudo apt update sudo apt install gcc g++
llama-cpp-python 安装命令
1
2
3
# 环境变量 CMAKE_ARGS="-DLLAMA_CUBLAS=on" 是为了使用 cuBLAS 库
# [server] 是为了支持启动类 openai-api 的接口服务
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python[server]
下载模型
目前最新版本的 llama.cpp 仅支持 GGUF 格式的模型,但是 CodeFuse 官方只提供了 GPTQ 格式的量化模型。您可以从这个链接下载所需要的 GGUF 格式的模型:https://huggingface.co/TheBloke/CodeFuse-CodeLlama-34B-GGUF,该模型提供了从最低 2bit 到最高 8bit 的多个量化版本,但请注意,精度会有所损失: | Name | Quant method | Bits | Size | Max RAM required | Use case | | — | — | — | — | — | — | | codefuse-codellama-34b.Q2_K.gguf | Q2_K | 2 | 14.21 GB | 16.71 GB | smallest, significant quality loss - not recommended for most purposes | | codefuse-codellama-34b.Q3_K_S.gguf | Q3_K_S | 3 | 14.61 GB | 17.11 GB | very small, high quality loss | | codefuse-codellama-34b.Q3_K_M.gguf | Q3_K_M | 3 | 16.28 GB | 18.78 GB | very small, high quality loss | | codefuse-codellama-34b.Q3_K_L.gguf | Q3_K_L | 3 | 17.77 GB | 20.27 GB | small, substantial quality loss | | codefuse-codellama-34b.Q4_0.gguf | Q4_0 | 4 | 19.05 GB | 21.55 GB | legacy; small, very high quality loss - prefer using Q3_K_M | | codefuse-codellama-34b.Q4_K_S.gguf | Q4_K_S | 4 | 19.15 GB | 21.65 GB | small, greater quality loss | | codefuse-codellama-34b.Q4_K_M.gguf | Q4_K_M | 4 | 20.22 GB | 22.72 GB | medium, balanced quality - recommended | | codefuse-codellama-34b.Q5_0.gguf | Q5_0 | 5 | 23.24 GB | 25.74 GB | legacy; medium, balanced quality - prefer using Q4_K_M | | codefuse-codellama-34b.Q5_K_S.gguf | Q5_K_S | 5 | 23.24 GB | 25.74 GB | large, low quality loss - recommended | | codefuse-codellama-34b.Q5_K_M.gguf | Q5_K_M | 5 | 23.84 GB | 26.34 GB | large, very low quality loss - recommended | | codefuse-codellama-34b.Q6_K.gguf | Q6_K | 6 | 27.68 GB | 30.18 GB | very large, extremely low quality loss | | codefuse-codellama-34b.Q8_0.gguf | Q8_0 | 8 | 35.86 GB | 38.36 GB | very large, extremely low quality loss - not recommended |
笔者下载的是 codefuse-codellama-34b.Q4_K_M.gguf 版本,网盘下载 https://www.123pan.com/s/HcuEjv-Cfw3A.html
启动 api 服务
1
2
3
4
5
6
7
8
9
10
11
# --model 指定模型路径
# --n_gpu_layers 指定模型的多少层使用 GPU 进行推理
# CodeFuse-CodeLlama-34B 模型总共有 51 层,如果全部使用 gpu 推理则设置大于等于 51 即可
# 如果显存不够,可以适当调低,剩余层数则会加载到内存,由 cpu 进行推理。
# --n_ctx 用于设置模型的最大上下文大小,默认值是 512 个token。
# --host 指定服务地址,默认为 127.0.0.1(只有本机可以访问),如果想要网络其他机器可以访问可设置为 0.0.0.0
# --port 指定服务端口
python -m llama_cpp.server --model /models-path/codefuse-codellama-34b.Q4_K_M.gguf --n_gpu_layers 100 --host 0.0.0.0 --port 8080 --n_ctx 2048
如果启动过程不出错,就可以使用了。
通过 Chatbox 进行对话
安装
如果没有安装 Chatbox,可从 Chatbox下载链接 下载安装。
设置
选择 openapi api 接口,api-key 为空即可,具体如下截图: 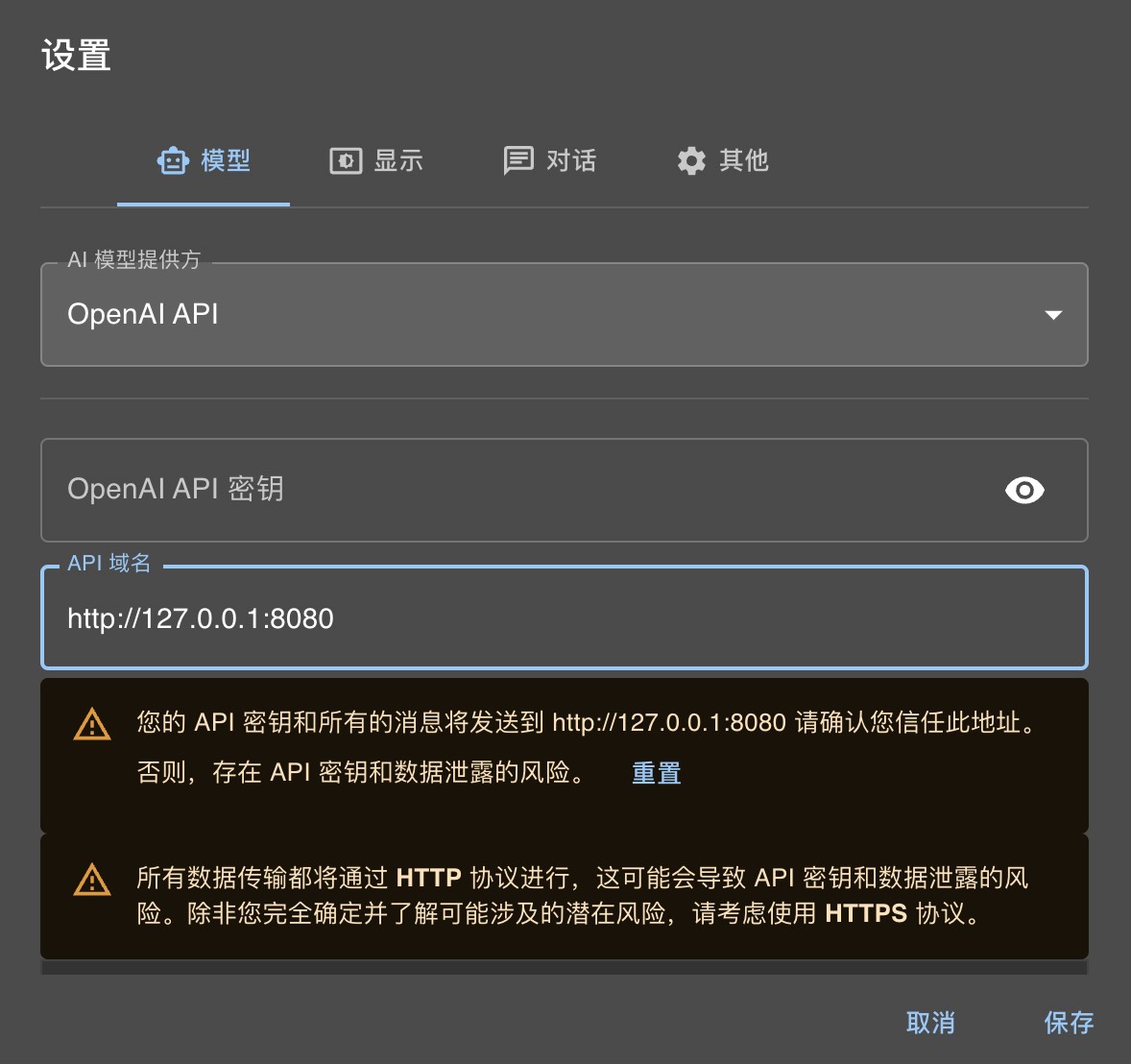
模型有关参数设置 
具体可以根据自己的情况设置。
然后就可以愉快的对话了。
