本方案采用 llamafile 的格式,只需单个文件即可跨平台运行模型,并提供 webui 界面和类 openai api 服务。极大的降低了使用门槛。关于 llamafile 可参考 llamafile使用指南 或者 项目地址 。
1. 第一步:下载 LLaVA-1.5-7B 模型
这个模型是 70 亿参数的 int4 量化版本,3.99GB。
2. 第二步:运行 LLaVA-1.5-7B 模型
Windows 系统
- 修改文件名,增加
.exe后缀,如改成llava-v1.5-7b-q4.exe - 打开
cmd或者terminal命令行窗口,进入模型所在目录
1
.\llava-v1.5-7b-q4.exe
- 浏览器打开
http://127.0.0.1:8080即可开始聊天
Linux、Mac 系统
- 终端运行(注意 Mac 系统可能需要授权,在【设置】→ 【隐私与安全】点击【仍然打开】进行授权)
1
./llava-v1.5-7b-q4.llamafile
- 浏览器打开
http://127.0.0.1:8080即可开始聊天
效果截图
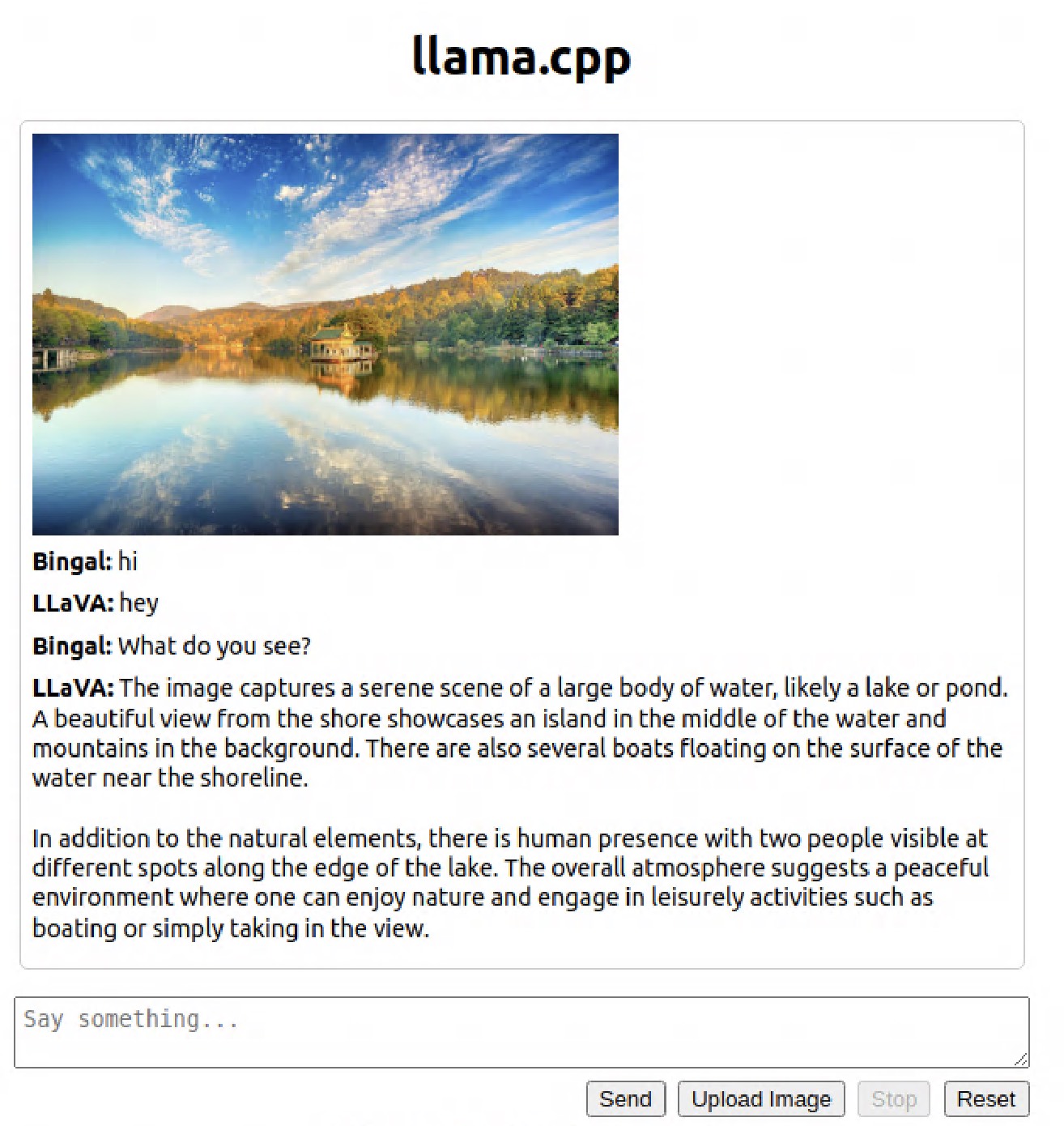
chatbox 等 gpt 客户端使用设置
选择 openai api,设置 url 为对应的 ip 和端口即可,如下图所示: 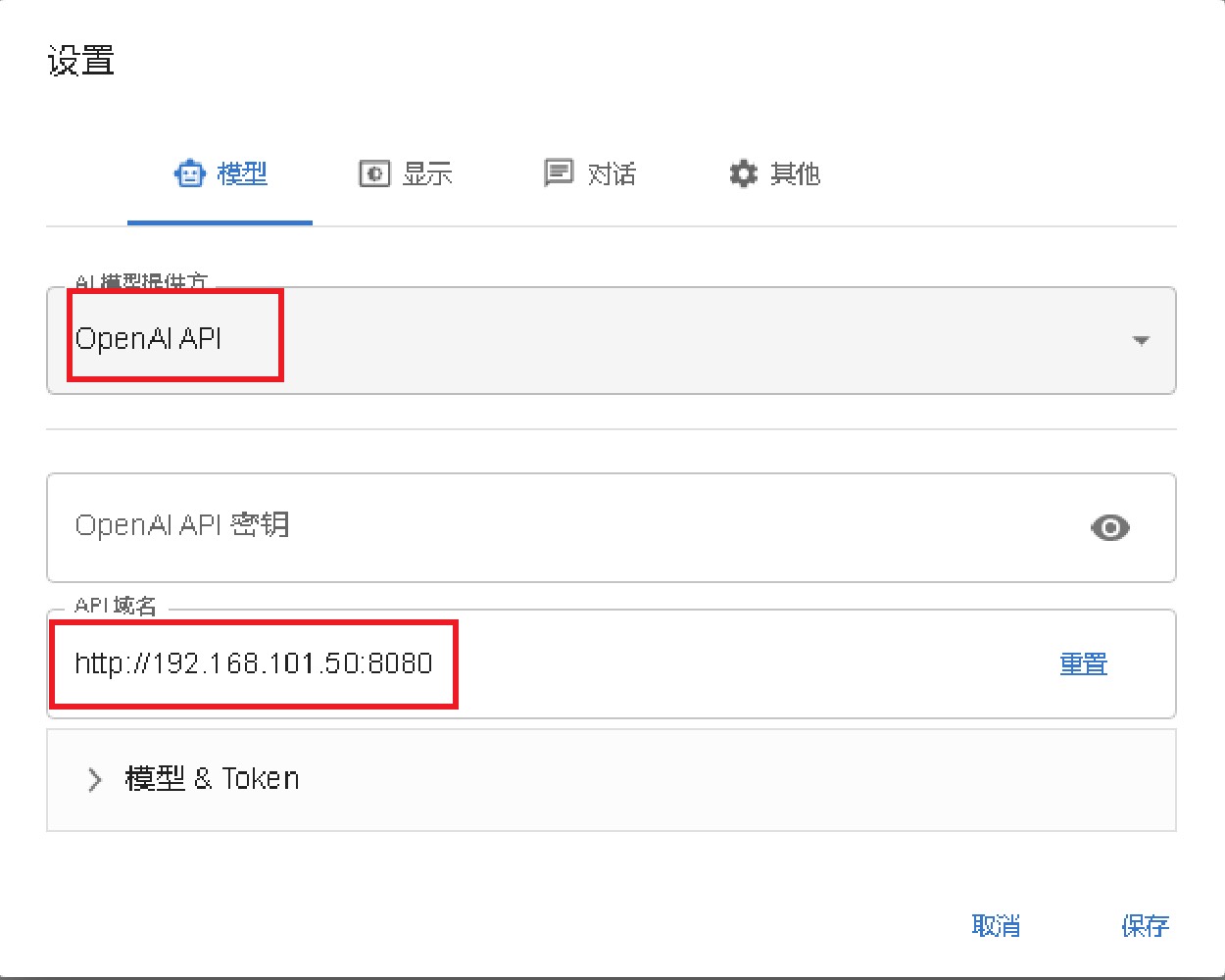
python 接口调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#!/usr/bin/env python3
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8080/v1", # "http://<Your api-server IP>:port"
api_key = "sk-no-key-required"
)
completion = client.chat.completions.create(
model="LLaMA_CPP",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "hello"}
]
)
print(completion.choices[0].message)
可选参数说明
-ngl 999表示模型的多少层放到 GPU 运行,其他在 CPU 运行,如果没有 GPU 则可设置为-ngl 0,默认是 999,也就是全部在 GPU 运行(需要装好驱动和 CUDA 运行环境)。--host 0.0.0.0web 服务的hostname,如果只需要本地访问可设置为--host 127.0.0.1,默认是0.0.0.0,即网络内可通过 ip 访问。--port 8080web服务端口,默认8080,可通过该参数修改。-t 16线程数,当 cpu 运行的时候,可根据 cpu 核数设定多少个内核并发运行。- 其他参数可以通过
--help查看。
其他可独立运行的模型大集合

真诚邀请您走进我的知识小宇宙,关注我个人的公众号,在这里,我将不时为您献上独家原创且极具价值的技术内容分享。每一次推送,都倾注了我对技术领域的独特见解与实战心得,旨在与您共享成长过程中的每一份收获和感悟。您的关注和支持,是我持续提供优质内容的最大动力,让我们在学习的道路上并肩同行,共同进步,一起书写精彩的成长篇章!
